



爬取腾讯视频
阅读:4825 分享到我们的自动赚钱项目主要分为两部分:第 1 部分是素材收集,我们写程序从腾讯视频上收集我们想要的短视频素材;第 2 部分上传到公众号,我们写程序把爬下来的腾讯视频素材上传到公众号上。
现在我们先从第 1 部分开始,腾讯视频有各种分类题材,我们的程序可以爬取任何题材。惊不惊喜意不意外。
腾讯视频页面分析
从现在开始,我们就用刚刚所需的知识,正式开始我们赚钱项目的编程工作,首先我们打开腾讯视频的某个题材页面,下面是以黑科技题材为例,网址如下:
https://v.qq.com/channel/tech/list?filter_params=itype%3D6%26icompany%3D-1%26icelebrity%3D-1%26icolumn%3D-1%26sort%3D40&page_id=channel_list_second_page
我们在要爬取的视频上点击:右键--》检查;然后我们通过找规律发现每个视频对应 html 代码中的 class 等于 list_item 的 div 标签。
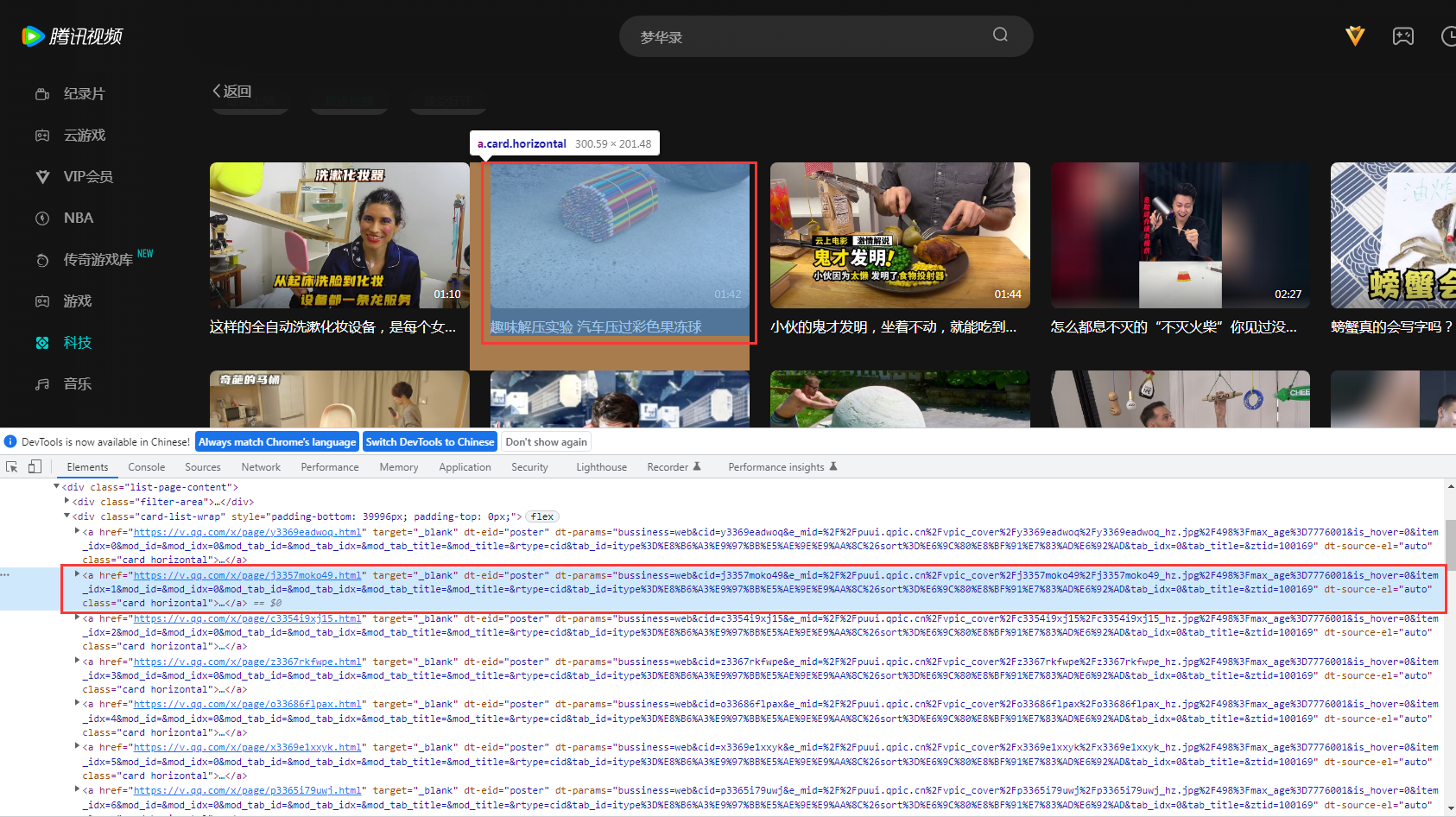
在此,我们要爬取视频的内容含有:视频链接,图片链接,视频时长,视频标题这四项内容。同样通过展开 div 标签,我们分别找到以上内容所对应的标签项。

根据我们前面所学的知识,轻易就可提取出来我们想要的内容,代码如下:
- find_element_by_tag_name('img').get_attribute("alt") # 视频名称
- find_element_by_class_name('figure').get_attribute("href") # 视频链接
- item.find_element_by_tag_name('img').get_attribute("src") # 图片链接
- find_element_by_class_name('figure_caption').text # 视频时长
到此为止,我们通过对腾讯视频页面的分析,已经掌握了我们要提取的信息,下面我们就开始写代码一步步把腾讯视频爬下来吧!
爬取视频题材
到此为止,我们通过对腾讯视频页面的分析,已经掌握了我们要提取的信息,下面我们就开始写代码一步步把腾讯视频爬下来吧!
第 1 步:导入selenium模块
把 selenium 模块导入到程序,因为后续的网页爬取和分析工作,我们使用的都是 selenium 提供的 API。
from selenium import webdriver
第 2 步:打开腾讯视频
使用 selenium 驱动 chromedriver 打开 chrome 浏览器,访问我们要爬取的腾讯视频页面。
viewtype = "地球最牛黑科技" url = "https://v.qq.com/channel/tech/list?filter_params=itype%3D6%26icompany%3D-1%26icelebrity%3D-1%26icolumn%3D-1%26sort%3D40&page_id=channel_list_second_page" viewdriver = webdriver.Chrome(executable_path="C:/driver/chromedriver.exe") viewdriver.get(url)
通过上面代码,我们发现程序中还定义了一个变量 viewtype,这个代表视频类型,方便我们自己做视频分类用的。
第 3 步:最大化浏览器窗口
前面我们刚刚讲过,用 selenium 模拟人操作浏览器,必定就和真人一模一样,如果浏览器内某个控件没有显露出来,我们人上网的时候就没法操作该控件(输入,拖动,点击等等),同样 selenium 也无法操作该控件,为了让所有的控件都显露出来,我们可以最大化浏览器。
viewdriver.maximize_window()
第 4 步:下拉滚动条
公众号每次只能发布 8 条视频,所以我们程序运行一次只需要爬取 8 条视频即可,然而,浏览器一个页面显示的腾讯视频个数不一定满足我们的要求(因为有好多视频是我们爬取过的,我们还要去重),我们为了爬取更多的视频,就需要不停的下来滚动条,让更多的视频显露在浏览器里面,这样我们就能爬取更多的视频了。
pullscrool(viewdriver, 0.03, 0.07)
下拉滚动条的代码需要我们自己写,下面是我写的通过 js 代码来拉动浏览器的滚动条,为了模拟的更像真人一样操作,我们每隔随机性的时间不停的往下拉动。
from selenium.webdriver.common.keys import Keys import random import time def pullscrool(driver, mintime, maxtime): # 腾讯视频页面屏蔽掉了滚动条,使用空格键下拉滚动条 try: # 先定位一个按钮才能使用空格下拉滚动条 tagx = driver.find_element_by_xpath('//div[@dt-eid="choose_item"][text()=" 最近热播 "]') tagx.click() except: pass # 先获取body元素,然后在该元素上面发送空格键 tag = driver.find_element_by_tag_name("body") for count in range(35): # 模拟空格键下拉滚动条 tag.send_keys(Keys.SPACE) time.sleep(random.uniform(mintime, maxtime)) # 取随机值更人性化
第 5 步:爬取所有视频标签
我们刚刚已经对腾讯视频页面进行了全面的分析,根据分析的结果,我们首先要把腾讯视频代码(html)页面中的视频项给爬下来,然后在从中提取我们需要的信息(视频名称,视频链接,视频图片,视频时长)。
viewstag = self.viewdriver.find_elements_by_class_name("horizontal")
代码很简单,就一句话!我们通过 selenium 提供的 API(find_elements_by_class_name),也就是把标签类名为 list_item 的所有标签给爬下来。
第 6 步:提取每个视频的信息(视频名称,视频链接,视频图片,视频时长)
通过第 5 步,我们已经获取了所有腾讯视频的标签项,然后,我们就可以从每个视频里面提取出我们想要的信息(视频名称,视频链接,视频图片,视频时长)。
for item in viewstag: viewname = item.find_element_by_class_name('title').text.strip() # 视频名称 viewlink = item.get_attribute("href") # 视频链接 viewimg = "https:" + item.find_element_by_tag_name('img').get_attribute("src") # 视频图片链接 viewtime = item.find_element_by_class_name('right-bottom-text').text.strip() # 视频时长 viewslist.append([viewname, viewlink, viewimg, viewtime, viewtype])
上面代码,我们通过一个 for 循环,把所有视频标签项里面的我们所需要的四个信息都提取出来了,然后存储到一个 viewslist 变量里面。
第 7 步:判断爬够 8 个视频,退出爬取腾讯视频逻辑。
我们每爬取解析一个视频信息,就让计数加 1,直到爬取解析 8 个视频的时候,我们就退出循环,退出循环的语句是 break。
viewcount += 1 # 每次循环已经解析过的视频个数加1 if viewcount >= maxviewcount: # 如果够8个就退出循环 break
viewscount 变量是当前已经解析了第几个视频,初始化为 0,maxviewscount 变量是我们当天爬取最大视频量,初始化为 8,这两个变量要在 for 循环外面定义好。
viewcount = 0 # 当前已解析的视频数量 maxviewcount = 8 # 当天最大视频数量
到目前为止,我们已经完成了爬取腾讯视频,并且把每个腾讯视频项里面的信息(视频名称,视频链接,视频图片,视频时长)给提取出来了。万里长征的第一步我们已经完成,很轻松,很简单,是不是很有成就感。
存储视频信息到数据库
我们获取腾讯视频信息的目的,是为了把这些信息上传到公众号上去,所以我们需要把这些信息存储起来,以方便后续我们在上传公众号时使用。现在我们就开始介绍如何把这些信息存储到数据库中。
在使用数据库前,我们需要先安装数据库,我们在此使用 mysql 数据库,安装和配置方法请参考mysql 安装和配置 ,在此我已经把数据库安装到阿里云平台上了,大家可以直接使用,就不需要在本地安装了。我们需要用程序连接上数据库。
import pymysql gxviewdb = pymysql.connect(user='birdpython', # 登录数据库的用户名(换成你自己的) passwd='laoniao', # 登录数据库的密码(换成你自己的) db='gxview', # 要操作的数据库(换成你自己的) host='88.88.88.88', # 登录数据库的IP地址(换成你自己的) charset='utf8') # 指定编码格式为utf-8,否则显示乱码
我们使用了pymysql 模块的 connect 函数直接连接上了我们在阿里云的数据库,而 pymysql 模块在使用前,我们需要安装,安装命令如下:
pip install -i https://mirrors.aliyun.com/pypi/simple pymysql
我们在程序中已经连接上数据库,然后就可以把我们刚刚解析的每条视频的视频信息存储到数据库中了。
for views in viewslist: sql = 'insert gxviewtable(viewname, viewlink, viewimglink, viewlength, viewtype)' \ ' values ("%s", "%s", "%s", "%s", "%s")' % (views[0], views[1], views[2], views[3], views[4]) cursor = gxviewdb.cursor() cursor.execute(sql) gxviewdb.commit() cursor.close()
代码中,我们先定义一个 sql 语句,这个语句的意思是往数据库中插入视频名称,视频连接,图片链接,视频时长,视频类型等信息,然后在定义一个 cursor 光标执行这个 sql 语句,这样就可以把视频信息存储到数据库中了。
解决一些 bug 做一些优化
到目前为止,我们已经完成了腾讯视频的爬取,视频信息的提取和视频信息的存储,貌似我们已经完成关于我们赚钱项目的第一个任务。我们再仔细审核一下我们的项目,看看还有哪些没有考虑到的 bug 或者需要优化的地方:
- 1:如果我们已经使用了这些视频(这些信息上传到公众号),下次在爬取视频的时候,就不想再重新爬一遍了,也就是我们要对爬取的视频去重。
- 2:我们的公众号是做一些短视频的,如果爬取的腾讯视频过长或者过短,会影响我们公众号的质量,可能会损失掉一些客户,这是我们不想看到的,也就是说我们要控制短视频的时长。
视频去重
首先我们需要拿到所有的已经存储到数据库中的视频信息,然后和我们刚刚爬取的视频做对比,看看是不是有重复,如果重复我们就放弃掉该视频,再接着检查下一个,如果是新的视频,我们就把该视频信息存入到数据库中,一直这样下去。
为了对视频查重,我们没有必要把数据库中每条视频的所有信息都拿出来,我们只需要拿出视频的名称进行比较即可,下面代码是获取数据库中所有视频的名称。
cursor = gxviewdb.cursor() sql = "select viewname from gxviewtable" cursor.execute(sql) gxviewdbnames = cursor.fetchall() cursor.close()
拿到数据库中所有视频名称后,我们只需要判断当前爬取的视频的名称是不是已经被存储过了即可。
def judgeviewrepeat(viewname): if viewname in gxviewdbnames: return False else: return True
上面的 judgeviewrepeat 是一个函数,我们把代码写到里面,方便调用,代码的意思是,如果视频重复返回 False,否则返回 True,返回 True 说明是一条新的视频。
控制视频时长
我们对视频时间做一些优化,如果视频时长小于 50 秒或者视频时长大于 3 分钟,我们就放弃掉该视频,当然这个时长规则你可以自己定。
viewmintime = "00:50" viewmaxtime = "03:00" def judgeviewtime(viewtime): if viewmintime <= viewtime <= viewmaxtime: return True else: return False
上面代码,viewmintime 变量存储的值是最小视频时长,viewmaxtime 变量存储的值是最大视频时长。函数 judgeviewtime 的意思是:如果视频时长大于等于 viewmintime 小于等于 viewmaxtime 就返回 True,否则返回 False,返回 True 说明是符合条件的视频。
最后,我们在存储视频信息到数据库之前,要先调用我们刚刚写的视频时长判断的函数和视频查重判断的函数,符合要求后,再存储视频到数据库。
for item in viewstag: viewname = item.find_element_by_class_name('title').text.strip() # 视频名称 viewlink = item.get_attribute("href") # 视频链接 viewimg = "https:" + item.find_element_by_tag_name('img').get_attribute("src") # 视频图片链接 viewtime = item.find_element_by_class_name('right-bottom-text').text.strip() # 视频时长 if judgeviewtime(viewtime) and judgeviewrepeat((viewname,)): viewslist.append([viewname, viewlink, viewimg, viewtime, viewtype])
上面代码,我们先调用 judgeviewtime 函数和 judeviewrepeat 函数来规范视频时长和视频查重,符合条件的,我们再存储到 viewlist 里面,最后再把 viewlist 里面的视频信息存储到数据库中。
目前为止,我们已经把我们需求的素材爬下来并存储到数据库中,还做了一些优化解决了一些 bug, 大家按上面的代码流程就可以实现自动爬取功能了,如果有编程经验的同学可以用面向对象的方式重新组织一下代码。
如果以上内容对您有帮助,请老板用微信扫一下赞赏码,赞赏后加微信号 birdpython 领取免费视频。





