



pandas
阅读:121685313 分享到pandas 也是第三方模块,如果我们想使用它,必须先安装上该模块。安装方法: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas。
pandas 模块内有很多类库,这些类库里面实现了存储数据的属性和对数据进行运算的函数。
pandas 模块和 numpy 模块也很类似,都是对数据进行存储和运算的类,pandas 是一个强大的分析结构化数据的工具集;它的使用基础是 numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
数据结构和初始化
我们知道 numpy 支持一维数组和多维数组,无论什么维度的数据在 numpy 中都是存储成 ndarray 数据类型。pandas 同样也支持一维数组和多维数组,通常我们使用 pandas 操作一维数组和二维数组, pandas 提供 Series 数据类型存储一维数组,提供 DataFrame 数据类型来存储二维数组。
Series 是一种类似于一维数组的对象,是由一组数据(各种 numpy 数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的 Series 对象。
DataFrame 是一种类似于二维数组的对象,它是一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也有列索引,可以被看做是由 Series 组成的字典。
首先我们从一维数组开始学起,我们可以用 list, tuple, dict,numpy.ndarray 对象来初始化 pandas 的 Series 数据结构。
我们使用 list 初始化 Series,然后打印出结果和数据类型,结果左边的是 0,1,2 是 Series 的索引,这个索引,如果我们初始化的时候没有指定,pandas 会默认从 0 开始。
import pandas as pd listdata = ["hello", 888, "python"] data = pd.Series(listdata) print(data) print(type(data))
运行结果如下:
0 hello 1 888 2 python dtype: object <class 'pandas.core.series.Series'>
我们使用 tuple 初始化 Series,然后打印出结果和数据类型,发现和 list 的初始化方式雷同。
import pandas as pd tupdata = ("hello", 666, "python") data = pd.Series(tupdata) print(data) print(type(data))
运行结果如下:
0 hello 1 666 2 python dtype: object <class 'pandas.core.series.Series'>
我们使用 dict 初始化 Series,然后打印出结果和数据类型,我们发现 Series 的索引是我们初始化的时候给的字典的键。
import pandas as pd dicdata = {'a': 10, 'b': "python", 'c': 30} data = pd.Series(dicdata) print(data) print(type(data))
运行结果如下:
a 10 b python c 30 dtype: object <class 'pandas.core.series.Series'>
我们使用 numpy 的 ndaary 来初始化 Series,结果和使用 list,tuple 雷同,由于没有指定索引,Series 也是使用 pandas 默认的索引。
import numpy as np import pandas as pd nparr = np.arange(3, 6) data = pd.Series(nparr) print(data) print(type(data))
运行结果如下:
0 3 1 4 2 5 dtype: int32 <class 'pandas.core.series.Series'>
设置索引
我们发现使用 dict 初始化 Series 时,dict 的键自动成为了 Series 的索引,这样看起来很清晰,如果使用 list,tuple 或者 ndarry 初始化 Series 时,我们不想使用默认的索引,而是想自己指定索引该怎么办呢,这个时候我们可以给初始化函数 Series(注意:这是个函数,只是这个函数名和我们 Series 对象重名)传入一个参数 index 来指定。
import pandas as pd listdata = ["hello", 888, "python"] data = pd.Series(listdata, index=['a', 'b', "c"]) print(data)
运行结果如下:
a hello b 888 c python dtype: object
上面的例子中,我们通过 index 参数指定索引为 a,b,c 通过结果我们发现索引已经指定成功。注意,我们给定的索引个数要和数据的个数一样,否则会报错。
使用 tuple 或 ndaary 类型指定索引的方法和 list 相同,在此不在举例,大家可以自己写代码试验一下。
我们在使用 dict 初始化 Series 时,也可以传入一个参数 index, 这样一来,pandas 重新按照给定的 index 的顺序来调整 dict 的键成为新的索引。结果如下图,我们发现 Series 索引的顺序已根据 index 给定的顺序调整为b,c,a。
import pandas as pd dicdata = {'a': 10, 'b': 20, 'c': 30} data = pd.Series(dicdata, index=['b', 'c', 'a']) print(data)
运行结果如下:
b 20 c 30 a 10 dtype: int64
在使用 dict 初始化 Series 时,当我们给定的 index 参数中没有 dict 的键时,则会去除掉 dict 中键对应的这一项(索引和值),而新增的 index 参数的值作为新的索引对应的值为 NaN,而且整个 Series 的值都被 pandas 改成了浮点类型。结果如下图,我们发现 dictdata 的 "a": 10 这一项被去掉了,在 index 中我们新增加的索引 d 和 e 加入到了 Series 中,对应的值被 pandas 默认为 NaN,整个 Series 的值也变成了浮点类型。
运行结果如下:
b 20.0 c 30.0 d NaN e NaN dtype: float64
访问方法
我们初始化 Series 之后,肯定要使用其中的数据,那该如何获取数据呢,就如我们定义了字典,想访问字典中的值一样,我们可以使用字典的键来访问字典中的值,同样我们是通过 Series 中的索引来访问 Series 中的值,访问方法也类似字典。
import pandas as pd dicdata = {'a': 10, 'b': 20, 'c': 30} data = pd.Series(dicdata) print(data['b']) print(data['a']) print(data['c'])
运行结果如下:
20 10 30
我们的 Series 要比字典强大的多,比如,我们可以通过多个索引同时访问多个值。注意:我们通过多个索引得的值是 Series,类似取子集;而通过单个索引取得的是该索引对应的值。
import pandas as pd dicdata = {'a': 10, 'b': 20, 'c': 30} data = pd.Series(dicdata) print(data[['a', 'c']])
运行结果如下:
a 10 c 30 dtype: int64
我们也想像 list,tuple 一样通过下标来访问 Series。注意,我们不能通过多个下标同时访问 Series。
import pandas as pd dicdata = {'a': 10, 'b': 20, 'c': 30} data = pd.Series(dicdata) print(data[2])
运行结果如下:
30
无论是通过索引还是通过下标访问 Series 时,如果给定的索引不存在或者下标越界,程序都会报错。
import pandas as pd dicdata = {'a': 10, 'b': 20, 'c': 30} data = pd.Series(dicdata) print(data[3]) # 错误:下标越界 print(data['d']) # 错误:索引不存在
四则运算
Series 数据可以进行四则运算,Series 中参与运算的是索引对应的值,索引本身不参与运算。代码和结果如下图。通过结果我们发现,除法运算的结果为浮点数。
import pandas as pd dicdata1 = {'a': 4, 'b': 5, 'c': 6} dicdata2 = {'a': 1, 'b': 2, 'c': 3} data1 = pd.Series(dicdata1) data2 = pd.Series(dicdata2) print(data1 + data2) print(data1 - data2) print(data1 * data2) print(data1 / data2)
运行结果如下:
a 5 b 7 c 9 dtype: int64 a 3 b 3 c 3 dtype: int64 a 4 b 10 c 18 dtype: int64 a 4.0 b 2.5 c 2.0 dtype: float64
二维数组
DataFrame 是 pandas 存储二维数组的数据结构,它是 pandas 中最为常见、最重要且使用频率最高的数据结构,你可以想到它原型为电子表格或 SQL 表具有的结构。DataFrame 可以被看成是以 Series 组成的字典。它和 Series 的区别在于,不但具有行索引,且具有列索引。
DataFrame 在处理 Excel 数据或数据库数据方面使用比较广泛,我们知道这些数据都是有行列的,也就是二维数据。我们在做人工智能项目时,如果数据比较大,我们习惯于使用数据库或 excel,所以 DataFrame 在我们人工智能开发中也是非常重要的。
毋庸置疑,在学习一个新的数据类型时,我们首先要学的是如何初始化它,我们可以使用 list,tuple,dict, ndaary 或 series 来初始化 pandas 的 DataFrame。
我们使用 list 来初始化 DataFrame,本例中使用二维的 list 数组来初始化,代码和结果如下图。我们发现 DataFrame 的行索引是我们给出的 1 和 2,列索引是我们给出的 name,sex 和 age。
import pandas as pd listdata = [['如花', '男', 27], ["小花", "男", "30"]] data = pd.DataFrame(listdata, index=['1', '2'], columns=['name', 'sex', 'age']) print(data) print(type(data))
运行结果如下:
name sex age 1 如花 男 27 2 小花 男 30 <class 'pandas.core.frame.DataFrame'>
如果我们没有给出行索引或者列索引,pandas 会默认给出从 0 开始的整数开始计数。
import pandas as pd listdata = [['如花', '男', 27], ["小花", "男", "30"]] data = pd.DataFrame(listdata) print(data) print(type(data))
运行结果如下:
0 1 2 0 如花 男 27 1 小花 男 30 <class 'pandas.core.frame.DataFrame'>
下面我们使用一维的 list 数组初始化 DataFrame,代码和结果如下图。我们发现使用一维数组来初始化二维数组 DataFrame, DataFrame 的结果永远为一列,行的个数是一维数组的元素的个数。
import pandas as pd listdata = ['如花', '小花', '翠花'] data = pd.DataFrame(listdata) print(data) print(type(data))
运行结果如下:
0 0 如花 1 小花 2 翠花 <class 'pandas.core.frame.DataFrame'>
我们使用 tuple 来初始化 DataFrame 的方式和使用 list 雷同,在此我就不再赘述,同学们可以自行写代码试验。
我们可以使用 dict 来初始化 DataFrame,此时 dict 的键被 pandas 设置成 DataFrame 的列索引,行索引我们可以使用默认或者自己设定,代码和结果如下图。注意,给定的字典的每个键对应的数组元素个数必须一样,行索引的个数也必须和字典中键对应的数组的个数一样。
import pandas as pd dictdata = {"a": [1, 2, 3], "b": [4, 5, 6]} data = pd.DataFrame(dictdata, index=['x', 'y', 'z']) print(data)
运行结果如下:
a b x 1 4 y 2 5 z 3 6
在使用字典初始化 DataFrame 时,我们可以初始化函数中重新设置列索引(columns),如果设置的列索引的值和字典的键不相同,DataFrame 对应的值则为 NaN,columns 中遗漏的字典的键则在 DataFrame 中则去掉。
import pandas as pd dictdata = {"a": [1, 2, 3], "b": [4, 5, 6]} data = pd.DataFrame(dictdata, index=['x', 'y', 'z'], columns=['mm', 'b', 'nn']) print(data)
运行结果如下:
mm b nn x NaN 4 NaN y NaN 5 NaN z NaN 6 NaN
我们也可以使用键对应的值为非数组的字典来初始化 DataFrame,得到值的列数则为字典元素的个数,行数则根据给出的行索引 index 来决定,如下 DataFrame 的值为 3 行 2 列,因为我们给定的字典为 2 个元素,给定的行索引为 3 个元素。
import pandas as pd dictdata = {'one': 1, 'two': 2} data = pd.DataFrame(dictdata, index=['xx', 'yy', 'zz']) print(data)
运行结果如下:
one two xx 1 2 yy 1 2 zz 1 2
我们同样可以使用 numpy 的 2 维 ndarray 或 1 维 ndarray 初始化 DataFrame,初始化的方法类似 list 或 tuple,在此,我们使用 2 维 ndarray 初始化 DataFrame,代码和结果如下图。
import numpy as np import pandas as pd nddata = np.array([[2, 3, 4], [5, 6, 7]]) data = pd.DataFrame(nddata, index=['mm', 'nn'], columns=['x', 'y', 'z']) print(data)
运行结果如下:
x y z mm 2 3 4 nn 5 6 7
我们也可以使用 pandas 的 1 维数组 Series 初始化 DataFrame,Series 的行索引会被 pandas 设置为 DataFrame 的行索引,列索引可以默认也可以自己定义。
import pandas as pd seriesdata = pd.Series([1, 2, 4], index=["a", "b", "c"]) data = pd.DataFrame(seriesdata, columns=['x']) print(data)
运行结果如下:
x a 1 b 2 c 4
我们可以重新设定 DataFrame 的行索引,如果设置的行索引的值和 Series 的行索引不相同,DataFrame 对应的值则为 NaN,index 中遗漏的行索引值则在 DataFrame 中则去掉。
import pandas as pd seriesdata = pd.Series([1, 2, 3], index=["a", "b", "c"]) data = pd.DataFrame(seriesdata, index=["b", "x"], columns=['x']) print(data)
运行结果如下:
x b 2.0 x NaN
DataFrame 和常用的数据结构类似,还支持其它常用的操作,比如查找,修改,插入,删除等等,下面我们就来学习这些操作方法。
我们访问二维数组时,支持通过列索引访问,不支持通过行索引访问,更不支持通过下标访问(注意:pandas 的一维数组支持下标访问)。注意,通过单个列索引访问得到的结果的数据类型为 Series。
import pandas as pd dictdata = {'one': [1, 2, 3], 'two': [3, 2, 1]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) print(data["two"])
运行结果如下:
a 3 b 2 c 1 Name: two, dtype: int64
和字典类似,DataFrame 支持通过 get 函数取列索引访问,通过 get 方法访问和直接通过列索引访问的不同之处在于:如果访问的列索引不存在,get 会返回 None 值,而直接通过列索引访问则会报异常。
import pandas as pd dictdata = {'one': [1, 2, 3], 'two': [3, 2, 1]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) print(data.get("three"))
运行结果如下:
None
我们也可以通过多个列索引访问 DataFrame。注意,而通过多个列索引访问得到的结果的数据类型为 DataFrame。
import pandas as pd dictdata = {'one': [1, 2, 3], 'two': [3, 2, 1]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) print(data[['two']])
运行结果如下:
two a 3 b 2 c 1
DataFrame 的插入函数为 insert,我们可以给定列索引插入一列数值,代码和结果如下图所示。我们在位置 1(注意,DataFrame 的索引位置从 0 开始)的列索引处插入一列数据。注意,插入的列的元素个数必须和原有的列元素个数相同。
import pandas as pd dictdata = {'one': [1, 2, 3], 'two': [3, 2, 1]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) data.insert(0, 'three', [10, 20, 30]) # 在位置1插入一列,列的元素个数一定要匹配 print(data)
运行结果如下:
three one two a 10 1 3 b 20 2 2 c 30 3 1
注意,插入的列给定的索引位置不能越界,否则会报异常,比如上面的 DataFrame 数据有两列,可插入的列索引位置范围为 0 到 2。否则就会越界。如下代码,我们在索引位置3出插入一列,则会报异常。
import pandas as pd dictdata = {'one': [1, 2, 3], 'two': [3, 2, 1]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) data.insert(3, 'three', [10, 20, 30]) # 插入的位置 3 越界,报异常 print(data)
DataFrame 的删除函数为 pop,我们可以根据列索引删除一列元素,代码和结果如下图。注意,如果删除的列不存在,则会报异常。
import pandas as pd dictdata = {'one': [1, 2, 3], 'two': [3, 2, 1]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) data.pop('two') print(data)
运行结果如下:
one a 1 b 2 c 3
当然,DataFrame 还支持更多的函数操作,大家遇到需求时,可以自行查阅。最后回顾一下,我们发现 DataFrame 提供的增删改查操作都是列操作,其实大多数情况下,我们业务需求也是列操作。
文件读写
pandas 的 DataFrame 主要是为了处理二维数据 excel 或者数据库而产生的,所以我们在使用 DataFrame 进行文件的读写操作时,一般都是操作 excel 或者数据库。
DataFrame 提供了to_csv 函数,可以把 DataFrame 数据写到文件中,文件的格式为 csv,csv 格式和 excel 格式可以通用,代码如下。
import pandas as pd import numpy as np dictdata = {"id": [1001, 1002, 1003, 1004, 1005, 1006], "gender": ['male', 'male', 'male', 'female', 'male', 'female'], "pay": ['Y', 'N', 'Y', np.nan, 'Y', ''], "age": [21, 23, 20, 22, 19, 22]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c', 'd', 'e', 'f']) data.to_csv("data.csv")
运行程序后,我们用 excel 打开 data.csv 文件,结果如下图:
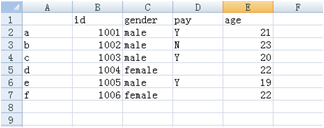
通过上面的结果,我们发现 csv 文件的内容的特点:DataFrame 的行索引成为了 csv 文件的第一列,列索引成为了文件的第一行(内容从第二个单元格开始),而且文件的内容默认是用逗号隔开,这样用 excel 打开后会自动区分单元格。
我们存储 DataFrame 数据到 csv 文件时,默认是以逗号作为分隔符。当然,我们也可以通过 sep 参数指定分隔符,如果指定的分隔符不是逗号,我们用 excel 打开该 csv 文件时,excel 没法区分单元格,代码如下。
import pandas as pd import numpy as np dictdata = {"id": [1001, 1002, 1003, 1004, 1005, 1006], "gender": ['male', 'male', 'male', 'female', 'male', 'female'], "pay": ['Y', 'N', 'Y', np.nan, 'Y', ''], "age": [21, 23, 20, 22, 19, 22]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c', 'd', 'e', 'f']) data.to_csv("data.csv", sep=";")
运行程序后,我们用 excel 打开 data.csv 文件,结果如下图:
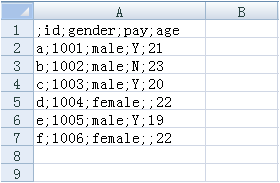
在上面代码中,我们指定分号作为每个内容的分隔符。此时我们用 excel 打开该 csv 文件,csv 文件内的所有内容都在 excel 的一个单元格内,因为 excel 只能以逗号作为单元格的分割符,所以,在无特殊需求情况下,我们都是用逗号隔开内容。
有时候,我们在存储 DataFrame 到 csv 文件中时,我们不想存储 DataFrame 的行索引,我们可以把 to_csv 函数中的 index 参数设置为 False 来完成这个需求。
import pandas as pd import numpy as np dictdata = {"id": [1001, 1002, 1003, 1004, 1005, 1006], "gender": ['male', 'male', 'male', 'female', 'male', 'female'], "pay": ['Y', 'N', 'Y', np.nan, 'Y', ''], "age": [21, 23, 20, 22, 19, 22]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c', 'd', 'e', 'f']) data.to_csv("data.csv", index=False)
运行程序后,我们用 excel 打开 data.csv 文件,结果如下图:

我们可以使用 DataFrame 提供的 read_csv 函数读取 csv 文件到 DataFrame 中,DataFrame 会使用自己的默认值作为行索引,而文件的第一行被作为 DataFrame 的列索引。比如有 data.csv 文件如下图
read_csv 函数读取 data.csv 文件到 DataFrame 中,然后打印。
import pandas as pd data = pd.read_csv("data.csv") # 函数读取的 excel 没有行索引。 print(data)
运行结果如下:
id gender pay age 0 1001 male Y 21 1 1002 male N 23 2 1003 male Y 20 3 1004 female NaN 22 4 1005 male Y 19 5 1006 female NaN 22
如果我们想让 csv 文件的第一列作为 DataFrame 的列索引,我们可以设置 read_csv 函数的 index_col 参数的值为 0。比如有 data.csv 文件如下图
read_csv 函数读取 data.csv 文件到 DataFrame 中,然后打印。
import pandas as pd # index_col=0 代表默认将数据的第一行当做列标签,指定第一个列元素为index_col的值的列作为索引 data = pd.read_csv("data.csv", index_col=0) print(data)
运行结果如下:
id gender pay age 0 1001 male Y 21 1 1002 male N 23 2 1003 male Y 20 3 1004 female NaN 22 4 1005 male Y 19 5 1006 female NaN 22
pandas 的 Series 也支持文件读写,使用方法和 DataFrame 雷同,Series 类型的数据是一维数组,只是我们很少做文件读写操作,在此就不一一介绍了。
我们知道 numpy 的 ndarray 类型的数据可以转为 list 类型的数据,pandas 的 DataFrame 类型数据则可以转为 dict 类型的数据,这种需求我们有时候也会用到。
import pandas as pd dictdata = {"id": [1001, 1002, 1003], "gender": ['male', 'male', np.nan]} data = pd.DataFrame(dictdata, index=['a', 'b', 'c']) dictdata = data.to_dict(orient='list') print(dictdata)
运行结果如下:
{'id': [1001, 1002, 1003], 'gender': ['male', 'male', nan]}
本节重要知识点
会初始化Series和DataFrame
会使用Series和DataFrame
掌握DataFrame的读写文件操作
如果以上内容对您有帮助,请老板用微信扫一下赞赏码,赞赏后加微信号 birdpython 领取免费视频。





