



MINIST数据集
阅读:1332666445 分享到通过前几章的学习,我们掌握了搭建神经网络的步骤,以及优化神经网络算法等知识点。在实际项目开发中,训练的数据也是非常重要的事情,我们一般很难通过自己生产出这些训练的数据。大家要相信这个世界有很多雷锋,很多公益组织搜集了各种各样的训练数据免费供给我们学习和使用,下面我们来学习如何下载和使用这些数据,以及这些数据的特点。
MNIST 数据集介绍
MNIST 数据集是麻省理工学院收集的各行各业的人手写数字(0-9)图片对应的特征值和标签, MNIST 数据集共有 7 万张手写数字图片以及对应的特征值和标签,我们一般使用 6 万张数据集作为训练集,1 万张数据集作为测试集。
MNIST 数据集中的手写图片都是黑底白字的灰度图片,如下图。

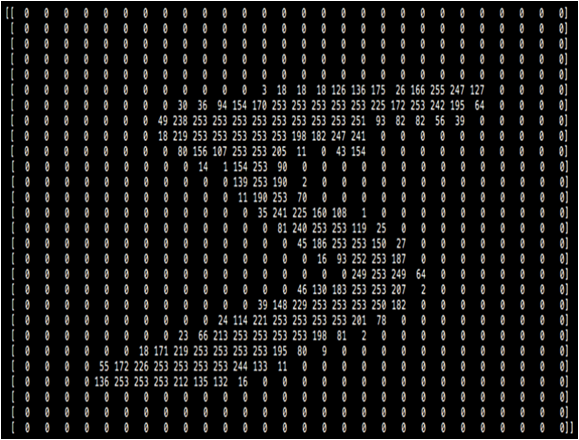
MNIST 数据集中每张图片都是根据 28*28 像素点的灰度值数据作为特征值,对应标签是 0-9 之间的数字。如手写图片 5,是根据一下形式提取出图片的特征值,得到的特征值是 28 行 28 列的二维矩阵。 0 表示纯黑色,255 表示纯白色。
MNIST 数据集下载和使用
tf 中提供了下载和使用 MNIST 数据集的 API,tf.keras.datasets.minist.load_data 函数可以返回 7 万个手写数字图片对应的数据集(6 万个训练集和 1 万个测试集)。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()
第一次运行 load_data() 函数时,该函数会检查你本机是否否已经下载了 MNIST 数据集,如果还没有下载,该函数会从 https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 网址自动下载该数据集,然后返回训练集和测试集;如果你本机已经有该数据集,该函数直接返回训练集和测试集。
因为该网址是外网,由于 gfw 的存在,同学们可能会下载失败,你可以从国内网站上下载该数据集,然后存放到 C:/用户/你的用户名/.keras/datasets 即可。
我们在以前的案例中使用的数据集中每一个特征值都是用向量的形式表示,同样,我们会把 MNIST 数据集中每一个二维的特征值都转为一个向量,以方便我们后面的计算,我们可以使用 tf.keras.layers.Flatten 函数把 28 行 28 列的矩阵转为一个含有 784 个元素的向量。

Flatten 是个函数对象,我们使用该函数对象就可以把训练集中的每一个二维矩阵转为一个向量,下面是使用 Flatten 把 6 万个训练集中的二维特征值转为一维特征值的代码。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() print("6万个训练集特征值shape:", x_train.shape) # (60000, 28, 28) flatten = tf.keras.layers.Flatten() x_train = flatten(x_train) # 展平 60000 个二维特征值为一维特征值 print("展平后6万个训练集特征值shape:", x_train.shape) # (60000, 784)
上面程序运行的结果如下:
6万个训练集特征值shape: (60000, 28, 28) 展平后6万个训练集特征值shape: (60000, 784)
因为 MNIST 数据集是 numpy 类型的数据,我们也可以使用 numpy 的 reshape 函数转为我们想要的 shape,比如整个训练集的特征值的 shape 为(60000,28,28),我们可以使用 reshape 转为 shape 为(60000, 784)。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() print("6万个训练集特征值shape:", x_train.shape) x_train = x_train.reshape(60000, 784) print("reshape后6万个训练集特征值shape:", x_train.shape)
上面程序运行的结果如下:
6万个训练集特征值shape: (60000, 28, 28) reshape后6万个训练集特征值shape: (60000, 784)
当然你也可以像 tf.keras.layers.Flatten 函数一样遍历每个特征值,然后使用 numpy 的 ravel 函数做展平操作,其实 tf.keras.layers.Flatten 就是调用的 numpy 的 ravel 函数。
我们可以使用 matplotlib 提供的 imshow 函数把特征值还原成图片,比如我们把训练集中第一个样本特征值还原成图片。
import tensorflow as tf import matplotlib.pyplot as plt mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() plt.imshow(x_train[0], cmap='gray') # 绘制灰度图 plt.show()
上面程序运行的结果如下图:
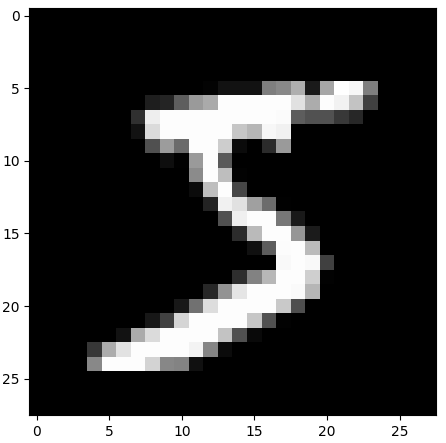
由结果我们可以看出,图片是个 28*28 像素的图片,因为我们特征值就是把手写图片分割成 28*28 个像素点,然后提取每个像素点的值组成的 28 行 28 列的矩阵。
我们把训练集中第一个样本的输入特征打印出来,代码如下。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() print("第一个样本的输入特征:\n", x_train[0])
程序运行的结果如下:
第一个样本的输入特征: [ [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0] [ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0] [ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0] [ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
通过打印的结果,我们发现它是一个 28*28 的二维数组,是手写数字 5 的 28 行 28 列的像素值,0 表示纯黑色,255 表示纯白色,而且从图形上看确实像一个数字 5。
下面我们分别打印出 x_train,y_train,x_test,y_test 的 shape,以便更清晰的了解 MNIST 数据集。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() # 整个训练集中特征值的shape print("x_train的shape:", x_train.shape) # 整个训练集中标签的shape print("y_train的shape:", y_train.shape) # 整个测试集中特征值的shape print("x_test的shape:", x_test.shape) # 整个测试集中标签的shape print("y_test的shape:", y_test.shape)
程序运行的结果如下:
x_train的shape: (60000, 28, 28) y_train的shape: (60000,) x_test的shape: (10000, 28, 28) y_test的shape: (10000,)
下面我们使用 tensorflow 的高阶 API keras 来实现手写数字识别的神经网络训练,我们还是用六步法搭建神经网络。
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train / 255.0 # 转为(0.1)之间的小数更容易学习 x_test = x_test / 255.0 # 转为(0.1)之间的小数以适应训练好的神经网络 model = tf.keras.models.Sequential([ # 把每个二维特征值shape(28, 28)拉直为一维向量shape(784) tf.keras.layers.Flatten(), # 隐藏层使用relu激活函数,128自己设定的神经元个数,也就是w1的shape为(784, 128) tf.keras.layers.Dense(128, activation="relu"), # 输出层使用softmax激活函数,10分类所以是10个神经元,也就是w2的shape为(128, 10) tf.keras.layers.Dense(10, activation="softmax") ]) # model.compile(optimizer="adam", # 使用adam优化器 loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=["sparse_categorical_accuracy"]) # model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=2) model.summary()
程序运行的结果如下:
Epoch 1/5 1875/1875 [==============================] - 4s 2ms/step - loss: 0.2627 - sparse_categorical_accuracy: 0.9230 Epoch 2/5 1875/1875 [==============================] - 5s 3ms/step - loss: 0.1161 - sparse_categorical_accuracy: 0.9664 - val_loss: 0.1062 - val_sparse_categorical_accuracy: 0.9688 Epoch 3/5 1875/1875 [==============================] - 4s 2ms/step - loss: 0.0806 - sparse_categorical_accuracy: 0.9756 Epoch 4/5 1875/1875 [==============================] - 4s 2ms/step - loss: 0.0604 - sparse_categorical_accuracy: 0.9815 - val_loss: 0.0793 - val_sparse_categorical_accuracy: 0.9754 Epoch 5/5 1875/1875 [==============================] - 4s 2ms/step - loss: 0.0477 - sparse_categorical_accuracy: 0.9854 Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) multiple 0 _________________________________________________________________ dense (Dense) multiple 100480 _________________________________________________________________ dense_1 (Dense) multiple 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________
下面我们用类实现手写数字识别的神经网络训练,我们还是用六步法搭建神经网络。
import tensorflow as tf from tensorflow.keras.layers import Dense, Flatten from tensorflow.keras import Model mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train / 255.0 x_test = x_test / 255.0 class MnistModel(Model): def __init__(self): super(MnistModel, self).__init__() self.flatten = Flatten() self.d1 = Dense(128, activation="relu") self.d2 = Dense(10, activation="softmax") def call(self, x): x = self.flatten(x) a = self.d1(x) y = self.d2(a) return y model = MnistModel() model.compile(optimizer="adam", # 使用adam优化器 loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=["sparse_categorical_accuracy"]) model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1) model.summary()
程序运行的结果如下:
Epoch 1/5 1875/1875 [==============================] - 5s 3ms/step - loss: 0.2608 - sparse_categorical_accuracy: 0.9255 - val_loss: 0.1453 - val_sparse_categorical_accuracy: 0.9569 Epoch 2/5 1875/1875 [==============================] - 5s 2ms/step - loss: 0.1162 - sparse_categorical_accuracy: 0.9653 - val_loss: 0.0958 - val_sparse_categorical_accuracy: 0.9713 Epoch 3/5 1875/1875 [==============================] - 5s 3ms/step - loss: 0.0791 - sparse_categorical_accuracy: 0.9760 - val_loss: 0.0880 - val_sparse_categorical_accuracy: 0.9739 Epoch 4/5 1875/1875 [==============================] - 4s 2ms/step - loss: 0.0603 - sparse_categorical_accuracy: 0.9817 - val_loss: 0.0881 - val_sparse_categorical_accuracy: 0.9745 Epoch 5/5 1875/1875 [==============================] - 5s 2ms/step - loss: 0.0468 - sparse_categorical_accuracy: 0.9853 - val_loss: 0.0763 - val_sparse_categorical_accuracy: 0.9770 Model: "mnist_model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) multiple 0 _________________________________________________________________ dense (Dense) multiple 100480 _________________________________________________________________ dense_1 (Dense) multiple 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________
其它数据集介绍
FASHION 数据集一共有 7 万张图片,每个图片都是 28 行 28 列像素点的灰度值数据,其中 6 万张 2828 像素点的衣裤等图片和标签用于训练;1 万张 2828 像素点的衣裤等图片和标签用于测试。

我们可以使用 tf.keras.datasets.fashion_mnist.load_data 函数获取 fashion 数据集,load_data 函数同样是从外网下载该数据集,无法下载的同学可以从国内网址下载,然后存放到:C:/用户/你的用户名/.keras/datasets /fashion-mnist 文件夹内即可,该数据集有四个文件。
FASHION 数据集的使用方法和 MNIST 数据集类似,我们只需要修改下载数据集的代码即可。
import tensorflow as tf fashion = tf.keras.datasets.fashion_mnist (x_train, y_train), (x_test, y_test) = fashion.load_data()
大家可以使用六步法自行写代码完成 FASHION 数据的训练。
思考
我们用 6 步法搭建神经网络,并使用 MNIST 数据集和 FASHION 数据集训练了网络参数,构建了具有识别智能的神经网络,从图上看我们已经掌握了这颗八股树中的树干。但是,在实际应用中,我们还需要解决相应的工程问题,我们需要给这个树干加上绿色的叶子,扩展它的功能,还要让这颗八股树结上丰富的果实。
前面的案例中,我们使用的训练集和测试集都是使用别人打包好的数据集,那么如果我们有了自己本领域的数据,我们该如何使用呢,针对这个问题,我们需要学会自制数据集。
如果我们的数据量过少,模型就会无法充分学习,泛化力就会过弱,针对这个问题,我们需要学会使数据增强。
如果有其它因素导致正在训练的程序停止,每次模型训练都从零开始是件很不划算的事情,我们需要实现断点续训,实时保存最优模型。
神经网络训练的目的就是获取各层网络最优的参数,只要有了这些参数,是可以在任何平台实现前向推力并能复现出模型实现应用的,我们需要学会参数提取并把参数持久化。
acc/loss 曲线可以见证模型的优化过程,我们需要 acc/loss 曲线的绘制功能以方便查看训练效果。
当以上都完成,我们能达到编写给图识物的应用程序,给神经网络输入一组新的,从未见过的特征,神经网络会输出预测的结果,实现学以致用。
总之,我们要完善这颗八股树,让其应用到项目工程中,需要解决一下问题。
1.自制数据集,解决本领域应用
2.数据增强,扩充数据集
3.断点续训,存取模型
4.参数提取,把参数存入文本
5.acc/loss可视化,查看训练效果
6.应用程序,给图识物
下一章,我们以手写数字识别项目来编码完善这个八股树。
本节重要知识点
掌握 MNIST 数据集的特点
会使用 MNIST 数据集搭建神经网络
会查找并使用其它数据集搭建神经网络
如果以上内容对您有帮助,请老板用微信扫一下赞赏码,赞赏后加微信号 birdpython 领取免费视频。





