



优化器
阅读:1234125494 分享到神经网络是基于连接的人工智能,当网络结构固定后,不同参数选取对模型的表达力影响很大,更新模型参数的过程,就像是在教一个孩子理解世界。长到一定年龄后的孩子,脑神经元的结构,规模是相似的,他们都具备了学习的潜力,但是不同的引导方法会让孩子具备不同的能力,从而达到不同的高度。优化器就是引导神经网络更新参数的工具,在此,我们来学习常用的神经网络参数优化器。
优化算法可以分成一阶优化和二阶优化算法,其中一阶优化就是指的梯度算法及其变种,而二阶优化一般是用二阶导数(Hessian 矩阵)来计算,如牛顿法,由于需要计算 Hessian 阵和其逆矩阵,计算量较大,因此没有流行开来。这里主要总结一阶优化的各种梯度下降方法。 深度学习优化算法经历了 SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam 这样的发展历程。
优化器的方法流程
在此,我们定义待优化参数为 w ,损失函数为 loss = f(w),初始学习率为 lr 或者α ,每次迭代一个 batch,t 表示当前 batch 迭代的总次数。
所有优化器的方法流程如下。
1.计算损失函数关于当前参数的梯度 。
2.根据历史梯度计算一阶动量和二阶动量 。
3.计算当前时刻的下降梯度 。
4.根据下降梯度进行更新 。
其中一阶动量是与梯度相关的函数,二阶动量是与梯度平方相关的函数。步骤 3,4 对于各 算法都是一致的,主要差别体现在步骤 1 和 2 上。
SGD 优化器
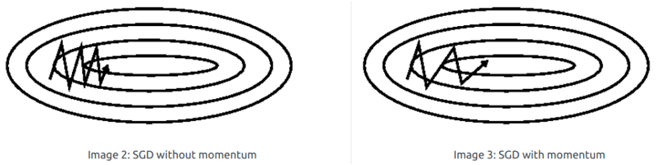
最初版本的 SGD 没有动量的概念,也叫 vanilla SGD(无momentum),是常用的梯度下降法,也是我们前面案例中一直使用的方法。

vanilla SGD 最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点。在神经网络训练中的代码实现如下(假定是个一层的神经网络,只有要更新的参数 w1 和 b1)。
# sgd w1.assign_sub(learning_rate * grads[0]) # 参数 w1 的自更新 b1.assign_sub(learning_rate * grads[1]) # 参数 b 的自更新
代码验证(同学们可以用两个指标来衡量该优化器在神经网络训练中的性能:占用的时间以及准确度)。
SGDM 优化器
动量法是一种使梯度向量向相关方向加速变化,抑制震荡,最终实现加速收敛的方法。为了抑制 SGD 的震荡,SGDM 认为梯度下降过程可以加入惯性。下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。SGDM 全称是 SGD with Momentum,在 SGD 基础上引入了一阶动量:
一阶动量是各个时刻梯度方向的指数移动平均值,约等于最近 个时刻的梯度向量和的平均值。也就是说,t 时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决 定。 的经验值为 0.9,这就意味着下降方向主要偏向此前累积的下降方向,并略微偏向当前时刻的下降方向。
在神经网络训练中的代码实现如下(假定是个一层的神经网络,只有要更新的参数 w1 和 b1)。
# sgd-momentun beta = 0.9 m_w = 0 m_b = 0 m_w = beta * m_w + (1 - beta) * grads[0] m_b = beta * m_b + (1 - beta) * grads[1] w1.assign_sub(learning_rate * m_w) b1.assign_sub(learning_rate * m_b)
代码验证(同学们可以用两个指标来衡量该优化器在神经网络训练中的性能:占用的时间以及准确度)
SGD 还有一个问题是会被困在一个局部最优点里。就像被一个小盆地周围的矮山挡住了视野,看不到更远的更深的沟壑。NAG 全称 Nesterov Accelerated Gradient,是在 SGD、SGDM 的基础上的进一步改进,改进点在于步骤 1。我们知道在时刻 t 的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步,那个时候再怎么走。
因此,NAG 在步骤 1 不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,考虑这个新地方的梯度方向。此时的梯度就变成了:。
我们用这个梯度带入 SGDM 中计算的式子里去,然后再计算当前时刻应有的梯度并更新这一次的参数。
上述 SGD 算法一直存在一个超参数(Hyper-parameter),即学习率。超参数是训练前需要手动选择的参数,前缀“hyper”就是用于区别训练过程中可自动更新的参数。学习率可以理解为参数 沿着梯度 反方向变化的步长。
SGD 对所有的参数使用统一的、固定的学习率,一个自然的想法是对每个参数设置不同的学习率,然而在大型网络中这是不切实际的。因此,为解决此问题,AdaGrad 算法被提出,其做法是给学习率一个缩放比例,从而达到了自适应学习率的效果(Ada = Adaptive)。其思想是:对于频繁更新的参数,不希望被单个样本影响太大,我们给它们很小的学习率;对于偶尔出现的参数,希望能多得到一些信息,我们给它较大的学习率。
那怎么样度量历史更新频率呢?为此引入二阶动量即在该维度上,所有梯度值的平方和:
回顾步骤 3 中的下降梯度: 可视为,即对学习率进行缩放。(一 般为了防止分母为 0 ,会对二阶动量加一个平滑项,即 ,是一个非常小的数)。
AdaGrad 优化器
AdaGrad 在稀疏数据场景下表现最好。因为对于频繁出现的参数,学习率衰减得快;对于稀疏的参数,学习率衰减得更慢。然而在实际很多情况下,二阶动量呈单调递增,累计从训练开始的梯度,学习率会很快减至 0,导致参数不再更新,训练过程提前结束。
在神经网络训练中的代码实现如下(假定是个一层的神经网络,只有要更新的参数 w1 和 b1)
# adagrad v_w = 0 v_b = 0 v_w += tf.square(grads[0]) v_b += tf.square(grads[1]) w1.assign_sub(learning_rate * grads[0] / tf.sqrt(v_w)) b1.assign_sub(learning_rate * grads[1] / tf.sqrt(v_b))
代码验证(同学们可以用两个指标来衡量该优化器在神经网络训练中的性能:占用的时间以及准确度)。
RMSProp 优化器
RMSProp 算法的全称叫 Root Mean Square Prop,是由 Geoffrey E. Hinton 提出的一种优化算法(Hinton 的课件见下图)。由于 AdaGrad 的学习率衰减太过激进,考虑改变二阶动量的计算策略:不累计全部梯度,只关注过去某一窗口内的梯度。修改的思路很直接,前面我们说过,指数移动平均值大约是过去一段时间的平均值,反映“局部的”参数信息,因此我们用这个方法来计算二阶累积动量:

在神经网络训练中的代码实现如下(假定是个一层的神经网络,只有要更新的参数 w1 和 b1)
# RMSProp beta = 0.9 v_w = 0 v_b = 0 v_w = beta * v_w + (1 - beta) * tf.square(grads[0]) v_b = beta * v_b + (1 - beta) * tf.square(grads[1]) w1.assign_sub(learning_rate * grads[0] / tf.sqrt(v_w)) b1.assign_sub(learning_rate * grads[1] / tf.sqrt(v_b))
AdaDelta 优化器
为解决 AdaGrad 的学习率递减太快的问题,RMSProp 和 AdaDelta 几乎同时独立被提出。AdaDelta 与 RMSprop 仅仅是分子项不同,为了与前面公式保持一致,在此用 表示 的均方根:
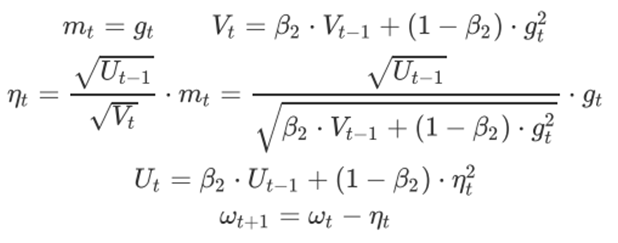
在神经网络训练中的代码实现如下(假定是个一层的神经网络,只有要更新的参数 w1 和 b1)
# AdaDelta beta = 0.999 v_w = 0 v_b = 0 u_w = 0 u_b = 0 v_w = beta * v_w + (1 - beta) * tf.square(grads[0]) v_b = beta * v_b + (1 - beta) * tf.square(grads[1]) delta_w = tf.sqrt(u_w) * grads[0] / tf.sqrt(v_w) delta_b = tf.sqrt(u_b) * grads[1] / tf.sqrt(v_b) u_w = beta * u_w + (1 - beta) * tf.square(delta_w) u_b = beta * u_b + (1 - beta) * tf.square(delta_b) w1.assign_sub(delta_w) b1.assign_sub(delta_b)
代码验证(同学们可以用两个指标来衡量该优化器在神经网络训练中的性能:占用的时间以及准确度)。
adam 优化器
adam 融合了Adagrad 和 RMSprop 的思想。谈到这里,Adam 的出现就很自然而然了——它们是前述方法的集大成者。我们看到,SGDM 在 SGD 基础上增加了一阶动量,AdaGrad、RMSProp 和 AdaDelta 在 SGD 基础上增加了二阶动量。把一阶动量和二阶动量结合起来,再修正偏差,就是 Adam 了。
SGDM的一阶动量: 加上 RMSProp 的二阶动量:
其中,参数经验值是:,
一阶动量和二阶动量都是按照指数移动平均值进行计算的。初始化,,在初期,迭代得到的, 会接近于 0。我们可以通过对, 进行偏差修正来解决这一问题。

在神经网络训练中的代码实现如下(假定是个一层的神经网络,只有要更新的参数 w1 和 b1)
# adam m_w = 0 m_b = 0 v_w = 0 v_b = 0 beta1 = 0.9 beta2 = 0.999 delta_w = 0 delta_b = 0 global_step = 0 m_w = beta1 * m_w + (1 - beta1) * grads[0] m_b = beta1 * m_b + (1 - beta1) * grads[1] v_w = beta2 * v_w + (1 - beta2) * tf.square(grads[0]) v_b = beta2 * v_b + (1 - beta2) * tf.square(grads[1]) m_w_correction = m_w / (1 - tf.pow(beta1, int(global_step))) m_b_correction = m_b / (1 - tf.pow(beta1, int(global_step))) v_w_correction = v_w / (1 - tf.pow(beta2, int(global_step))) v_b_correction = v_b / (1 - tf.pow(beta2, int(global_step))) w1.assign_sub(learning_rate * m_w_correction / tf.sqrt(v_w_correction)) b1.assign_sub(learning_rate * m_b_correction / tf.sqrt(v_b_correction))
代码验证(同学们可以用两个指标来衡量该优化器在神经网络训练中的性能:占用的时间以及准确度)。
如何选择优化器
很难说某一个优化器在所有情况下都表现很好,我们需要根据具体任务选取优化器。一些优化器在计算机视觉任务表现很好,另一些在涉及 RNN 网络时表现很好,甚至在稀疏数据情况下表现更出色。
总结上述,基于原始 SGD 增加动量和 Nesterov 动量,RMSProp 是针对 AdaGrad 学习率衰减过快的改进,它与 AdaDelta 非常相似,不同的一点在于 AdaDelta 采用参数更新的均方根(RMS)作为分 子。Adam 在 RMSProp 的基础上增加动量和偏差修正。如果数据是稀疏的,建议用自适用方法,即 Adagrad, RMSprop, Adadelta, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。随着梯度变的稀疏,Adam 比 RMSprop 效果会好。总的来说,Adam 整体上是最好的选择。
优化算法的常用策略:
首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑 SGD + Nesterov Momentum 或者 Adam。
选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。
充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用 Adam 进行快速实验优化;在模型上线或者结果发布前,可以用精调的 SGD 进行模型的极致优化。
先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
考虑不同算法的组合。先用 Adam 进行快速下降,而后再换到 SGD 进行充分的调优。
充分打乱数据集(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。在每一轮迭代后对训练数据打乱是一个不错的主意。
训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者 AUC 等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数 据的监控是为了避免出现过拟合。
制定一个合适的学习率衰减策略。可以使用分段常数衰减策略,比如每过多少个 epoch 就衰减一次;或者利用精度或者 AUC 等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
Early stopping。如 Geoff Hinton 所说:“Early Stopping 是美好的免费午餐”。你因此必须在训练的过程中时常在验证集上监测误差,在验证集上如果损失函数不再显著地降低,那么应该提前结束训练。
算法参数的初始值选择。初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
总之,就如泡妞一样,根据自身条件调整不同策略:长得帅可以强吻;钱多可以撒币;情商高可以甜言蜜语;有权有势可以给对方家里安排工作等等。没有最好的策略只有合适的策略。
本节重要知识点
掌握 SGD 优化器。
掌握 adam 优化器。
了解其它几种优化器。
知道如何选择优化器。
如果以上内容对您有帮助,请老板用微信扫一下赞赏码,赞赏后加微信号 birdpython 领取免费视频。





